Feature monitoring
Description
There are at least three kinds of monitoring that a developer cares about:
- Application performance monitoring (APM)
- System monitoring
- Business metrics/analytics
What I'm excited about is a 4th kind, which I'm calling "feature monitoring". Being able to know after shipping a merge request that we didn't blow up production. Or that error rates grew by 5% after enabling a feature flag on a subset of users.
Proposal
Here are three potential evolutions:
- Measure before/after deploying merge request and attribute any changes to the relevant merge request(s)
- Canary deploys where new features (via merge requests) can be shipped to a portion of a production fleet so they get real traffic, then monitor, report, and alert on differences in performance.
- Feature flags to ship one or more merge requests behind a flag that can be enabled for a portion of production users, then monitor, report, and alert on differences in performance.
Links / references
- Feature deploys: https://gitlab.com/gitlab-org/gitlab-ee/issues/779
- Related: #23841 (closed)
- Original vision: https://about.gitlab.com/direction/cicd/#monitor
- Feature deploys: https://gitlab.com/gitlab-org/gitlab-ee/issues/779
Activity
/cc @tauriedavis @awhildy for far-reaching stuff for UX to think about.
Mentioned in issue #24344 (closed)
Mentioned in issue gitlab-com/www-gitlab-com#871 (closed)
Mentioned in issue #25190 (closed)
Awesome to have this, slightly related related to the deployboard https://gitlab.com/gitlab-org/gitlab-ce/issues/21413
mentioned in issue #25387 (closed)
I think feature monitoring falls under the other categories you've listed. When my MR is merged I want to know (in this order):
- whether I didn't blow up an environment https://gitlab.com/gitlab-org/gitlab-ce/issues/25555
- what the system impact is
- what the application impact is
- how the immediate business metrics change (big change in behaviors? conversions)
- how the long term business metrics change (uptake in conversions / revenue?)
I made an issue for the first one https://gitlab.com/gitlab-org/gitlab-ce/issues/25555

It sounds like we have a number of different roads to take for this one. @markpundsack Can you review these user stories? Feel free to expand or adjust.
- As a user, I want the ability to see whether my MR caused the environment to go down after merging. https://gitlab.com/gitlab-org/gitlab-ce/issues/25555
- As a user, I want to be able to search for a MR and see the performance impact by plotting it on a graph that shows the response time, throughput, and memory of my application.
- As a user, I want to be able to deploy certain MRs to different end users and measure the differences in performance (response time, throughput, memory to start) between the group it was deployed to and the group it was not.
- As a user, I want to be able to group MRs to create feature flags that can be enabled and disabled easily to different sets of ends users while also measuring the differences in performances (response time, throughput, memory to start) per feature flag.
My question is, what do you need for the demo @markpundsack? #1 (closed) seems like a good first stage for the team but I'm unsure what you want to show for the demo. Can you provide a user story for your vision? Is there a demo script in the making?
@JobV I think you're right, if we stop at merge requests. But I want to go beyond point-in-time deploys and measuring impact before/after deploy of MRs. When you bring feature flags in, I think it fundamentally changes the monitoring capabilities because you can monitor certain aspects (like error rate) for people-with-the-flag and people-without-the-flag simultaneously. This reduces the external impact that time-based delineation is subject to.
@tauriedavis That's pretty close, but I'd rephrase it a bit. Feature flags aren't so much a bundling of MRs, as an in-code mechanism to conditionally execute one path or another (an if condition) based on externally controllable settings such as simple all-or-nothing binary switch, or a more complex incremental rollout involving named groups like "beta" and percentage rollouts.
From the vision doc:
My ideal rollout is something like:
- Dev team that created it ->
- internal alpha (all employees minus those giving customer-facing demos) ->
- select beta (~200 people that signed up for this specific feature) ->
- private beta (~1000 people that signed up for general beta) ->
- public beta ->
- 10% rollout ->
- GA
-
As a developer, I want the ability to see whether my MR caused the environment to go down after merging. #25555 (moved)
-
As a developer or ops, I want to see the performance impact (response time, throughput, and memory) of a merge request. e.g. by plotting a single graph with a vertical line showing the time of the deploy, or by showing separate before and after graphs, or by showing summary data from before/after the deploy.
-
As a developer or ops, I want to see the performance impact of a deploy by comparing before and after (in text summary and/or graphically).
-
(slight twise on above) As a developer or ops, I want to find which deploy caused reported problem by looking at a time graph and easily spotting which deploy caused a change, or by looking at a list of deploys and seeing a summary of each to easily find the recent deploy that caused a degradation.
-
As a developers, ops, or product manager, I want to decouple deployment from delivery so that I can control the rollout of functionality (which may span one or more MRs). e.g. Code can be put into production while the feature is still turned off. Features can then be rolled out to internal users, beta users, a percentage of production users, and then to everyone in ever-increases spheres.
-
As a developer or ops, I want to see the performance impact of a feature by comparing results for those with the feature enabled vs those that have it disabled.
-
As a developer or ops, I want to see the performance impact of a feature by comparing results before and after enabling.
-
As a developer, I want to be able to automatically rollback a feature (disable it for everyone) if performance is degraded too much.
Edited by Mark Pundsack@tauriedavis To get to your specific question, I'd like to see ideas for working feature flags into GitLab in a first-class way, and then showing some analysis/graphing on them. It might be too much to ask to work feature flags in generally, so focusing on graphs might be easier, but then again, the best interface may simply show a list of features and summary about them indicating if they're performing as expected. Like:
- Feature X, rolled out to
beta, decreased response time by 5% - Feature Y, rolled out to 10%, increased conversion by 25%
Then with click-throughs to see detailed graph information, maybe more system information, etc.
But also the MR stuff, since that's really valuable and an easier stepping stone in a lot of ways. Showing a list of deploys and their impact, or on an MR showing the before/impact. There was a screenshot of New Relic's deploy view somewhere...
- Feature X, rolled out to
mentioned in merge request gitlab-com/www-gitlab-com!4007 (merged)
@markpundsack I love how you can link a feature flag to an issue in http://docs.launchdarkly.com/docs/visual-studio-team-services-extension
Nice description of use cases https://github.com/launchdarkly/featureflags/blob/master/2%20-%20Uses.md
@sytses Yeah, those are great use cases, although I draw a pretty hard line that feature flags should only be temporary things as you develop a feature, not permanent permissions or capability settings. So the Subscription, Newbie vs Power User, and Maintenance Mode use cases really are different things and probably should use a different tool (or at least a different experience on top of the underlying capability). In Martin Fowler speak, it's the difference between
release toggles,experiment toggles,ops toggles, andpermissioning toggles.Also, I just discovered Split.io.
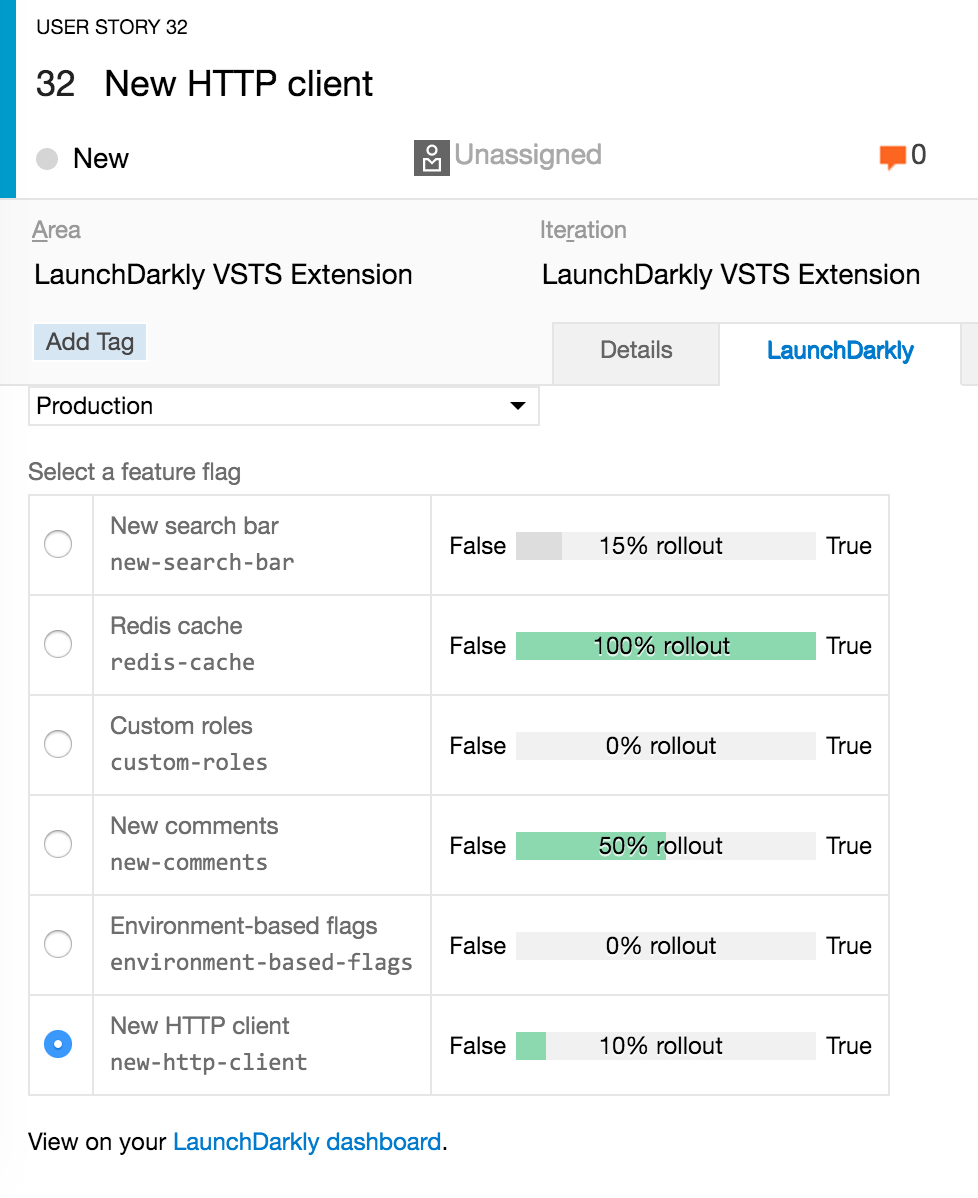
@tauriedavis Taking inspiration from http://docs.launchdarkly.com/docs/visual-studio-team-services-extension, specifically
, what do you think about linking a GitLab issue and/or MR to a feature flag, and then displaying the state of that flag across relevant environments? Kind of like how we show when a MR has been deployed to staging, we should show an info box saying that it has been rolled out to 10% on production. But since feature flags may span multiple MRs, tying it back to an issue may be more important.
Obviously there should be a feature flag list that shows the status of all flags, but deeply integrating into the issue and MR views would bring the context to the right place.
mentioned in issue #25424 (closed)